本文是HPCA 2018 RC-NVM: Enabling symmetric row and column memory accesses for in-memory databases1一文的学习总结与分析。这一部分将主要总结RC-NVM的总体架构设计。
值得注意的是,此架构设计的思路中,并不特定针对RC-NVM的电路设计,因而总体而言适用于不同的对称式存储器。
RC-NVM架构设计
内存架构的设计主要涉及:整体架构、寻址、缓存架构以及应用层的数据布局。
整体架构
类似于传统DRAM或RRAM内存,RC-NVM整体架构也有channel,DIMM,rank,chip,bank……的层次,关于内存的结构,可参见《内存条物理结构分析》一文的介绍。
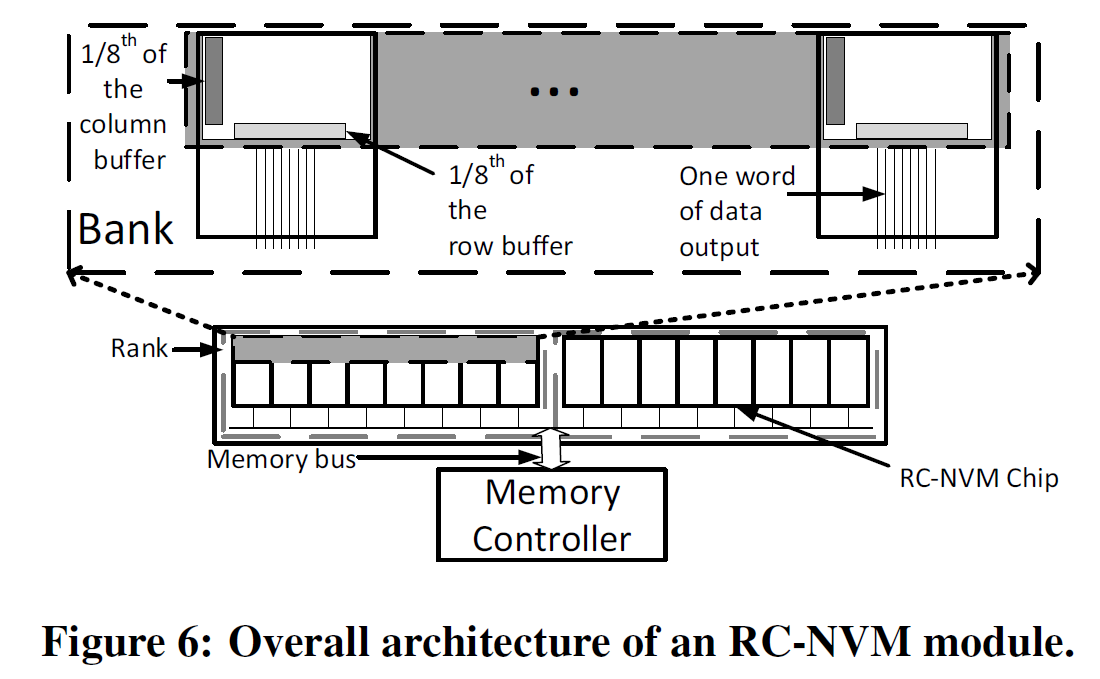
上图为RC-NVM整体架构的一个例子。此图中有一个DIMM,该DIMM中有两个rank,每个rank有八个chip,每个chip由上一篇总结中电路结构所示的bank(含多个RC-NVM子阵列)组成,八个chip合在一起形成64位的存储器总线。按行或按列的读取粒度(granularity)均为8字节。可以在每个rank添加一个chip用以安排纠错码,例如带附加奇偶校验码的汉明码(SECDED),则存储器总线为72位,和传统的DRAM一样。
寻址
寻址要完成三个目标:
- 两种读取方式的专用地址模式
- 显式控制物理内存上的数据布局
- 扩展指令集
双寻址模式
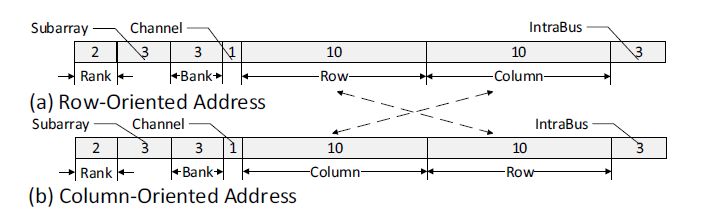
如图所示,(a)中是传统32位主存的地址格式,也即RC-NVM按行读取的地址,其与(b)中按列读取的地址在于:颠倒了行位和列位。传统地址格式被完全对称地移植到按列读取的方式上,简化了很多接口、控制器的设计,并且两种读取模式地址间的转换是很容易的。对于按行读取,内存地址增加是增加列位;对于按列读取,内存地址增加是增加行位。
显式数据布局控制
主流操作系统都有内存页的管理机制,现代处理器也支持这些机制。以huge-page(大内存页)技术为例,大内存页可以设为例如1GB,我们让大内存页中虚拟内存地址的低30位与对应物理内存地址低30位完全相同,那么当这低30位包含了行位和列位时(如上一节所示,这是可以做到的),那么分配内存空间时,IMDB(内存数据库)就可以显式地控制数据在物理内存上的布局。实际内存的子阵列(subarray)通常容量小于1GB,因而这样的策略是可以满足我们要求的。这里是以32位内存为例,64位内存是类似的。
我们为什么需要讨论数据布局的显式控制?事实上这是内存与操作系统接口部分的重要一环。实际的应用中,我们并不满足于直接操纵指针(虚拟地址)。在后面讨论具体应用的数据布局中,我们将看到,为了发挥对称式存储的优势,我们需要拥有显式控制数据布局的能力。我们在这里关心的是什么?是我们需要在操作系统调度、调配物理内存地址的时候,我们能够在应用层面,控制数据在物理内存上的布局。这个解决方式看似简单:直接将物理内存地址与虚拟内存地址直接对应,但需要知道这个对应不是毫无意义的;相反,失去了这个对应的限制,操作系统将直接全盘接管物理内存的调度分配,而我们将在应用层失去调整物理内存分配的可能。我们将在后面看到,像一维内存一样直接将数据按序存储将不是最优的布局方式,对称式存储器是真正二维的,因而针对不同应用进行显式的内存布局是必要的,将布局的能力交给应用处理显然是最合适的——我们不再简单地只在应用层分配内存,把具体数据布局交给操作系统(传统上数据也只需要顺序排列,不必考虑布局),而真正地接管了数据布局。
实际情况下,RC-NVM设备接入后,设备信息被传给BIOS,IMDB可以从操作系统处获得这些信息并且进行数据布局。
指令集扩展
这一部分较为简单,我们要增加cload和cstore指令,以利用我们按列读写的新特性。指令可形如:
1 | cload reg, addr |
其中reg为目标寄存器,addr为内存地址。指令的实际操作可以通过在行读和行写指令中加入一位信号,标识读写操作是按列的。这在DDR接口中是可以实现的,例如DDR4有两个预留的地址引脚,可以利用其中一个发送此信号。原先指令集中行读、行写仍分别为load和store,其它指令不需调整。
缓存架构
缓存架构主要也有三方面需要调整:
- 双寻址下的缓存存储方式
- 单核处理器的缓存同义
- 多核处理器的缓存同义与缓存一致性
双寻址下的缓存存储
RC-NVM在两个不同方向上,地址格式都与传统内存相同,因而缓存寻址也可以直接使用传统的方式,解码电路也不必更改。为了区分两个不同方向的地址,缓存中需要增加一个方向位(orientation bit),按行读取的数据方向位置0,按列读取的数据方向位置1。
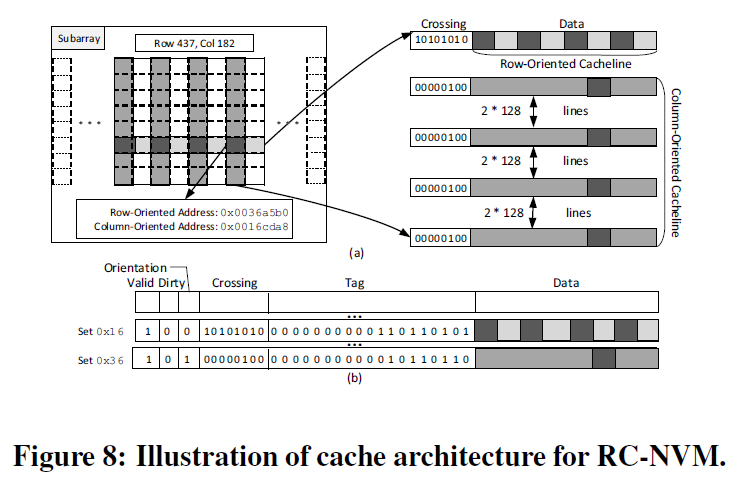
上图给出一个缓存的例子,第437行,182列的数据按先前的地址格式,按行读取为0x0036a5b0,按列读取为0x0016cda8,此处行位与列位均占10位,其余位为0。
这个例子中缓存大小64KB,块大小为64字节,4路相联,具体不再赘述,和传统缓存一致。每次按行读取某8字节数据时,将此子阵列中整行其它56字节一起读入缓存,同时置该缓存项的方向位为0;按列读取类似。
单核处理器的缓存同义问题
缓存同义(cache synonym)问题是指:按行读入缓存的数据与按列读入缓存的数据,交叉处的数据被存放在了两个缓存块中,而需要保持二者的同步。
在RC-DRAM的工作2中,提出了WURF 缓存一致性协议,以取代传统的MESI协议。RC-NVM的工作中提出了另一种方式:在缓存块中,给每个8字节(读取粒度)增加一位标识位,用以表示是否是交叉格,称为交叉位(crossing bit)。对每个64字节的缓存块,需要额外8位交叉位。在上图中有显示,对于缓存中读取的一行,其每8字节对应的交叉位指代缓存中是否有对应列存储其中。
总体而言,解决缓存同义,是要使得交叉处的数据同步更新。具体地,需要进行以下额外操作以保持同步:
- 当一个缓存块被载入缓存中,缓存控制器检查所有可能与此块交叉的行或列,并置交叉位,如果有交叉,那么交叉处的数据应由对应的缓存中复制而来(以保持同步)。例如上图,读取图示行时,检查所有8列,发现4列在缓存中,因而有四位交叉位置1。
- 当一个缓存块被从缓存中驱逐时,其交叉的行或列对应交叉位置0。
- 当一个缓存块在写操作中被更新,而更新位置对应的交叉位为1,对应的另一个缓存块同时更新数据。
多核处理器的缓存同义问题与缓存一致性问题
缓存一致性(cache coherence)问题是指:多核处理器各个私有缓存中存储同一份内存数据时,需要保持同步。
多核处理器中,既有缓存同义问题,又有缓存一致性问题。我们遵循以下原则:先处理缓存同义问题,再使用缓存一致性协议。
传统的缓存一致性协议主要分为监听式与目录式,此处不介绍细节。监听式主要通过监听其它处理器的缓存读写来调整自身的状态;目录式有一个主处理器以协调其它处理器的缓存,主处理器持有一个目录记录其它处理器的缓存信息。两种方式各有优劣,此处不做比较。对于RC-NVM,采用何种一致性协议是不重要的。
处理缓存同义问题的方式在上一节中已经叙述,对于多核是一样的。此处交叉位的值是否应该被视作缓存的一部分而应用缓存一致性协议呢?稍加思考可以知道:目录式的一致性协议需要将交叉位存于目录中,而监听式的协议需要将交叉位看为缓存块的一部分在各个核中同步更新。
处理完缓存同义问题后,我们再使用缓存一致性协议(例如MESI协议等),以保证各个核的缓存同步。注意到使用缓存一致性协议并不会引入新的缓存同义问题,因为缓存一致性问题仅涉及缓存块(某特定方向)的数据的同步,另一个方向应该已在先前的缓存同义中保证了交叉点的一致。另外,现有的缓存一致性协议不必修改。
另外,单核和多核情况下,从缓存读的操作均没有额外开销;写回额外开销不大;数据替换(更新)操作开销较大,但这本来开销就较大,故可以接受。(此部分开销的分析存疑,这里缓存读写的主要开销究竟是哪一项?)
具体应用
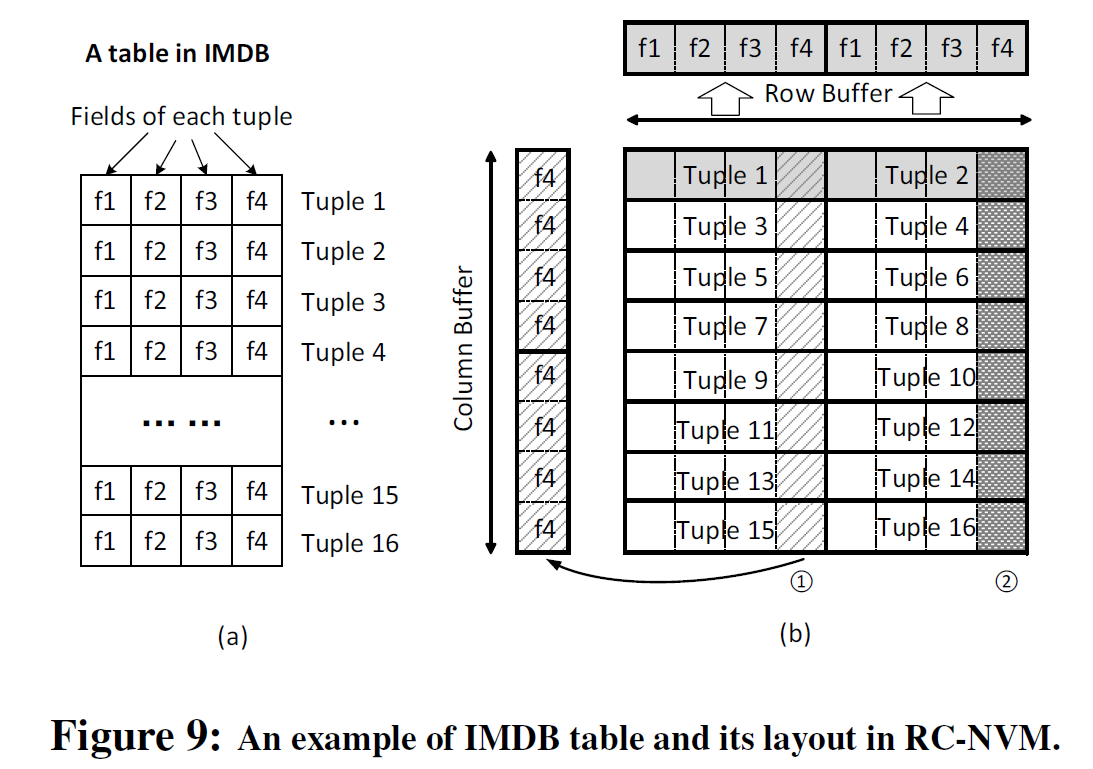
这是一个IMDB应用例,在这个应用中,如上所示,有16个数据项,每项4个字段,每个字段8字节,右侧的内存子阵列共含512字节,以如上布局存储16项数据。我们以以下几个应用为例说明RC-NVM的优势:
1 | 1 for (int i = 1; i <= 16; i++) { |
这是一个OLTP应用,选取所有f3字段小于'1234'的数据项,传统上按行依次读取比较,在RC-NVM上也是按行读取,每次读取,行缓冲区中可存两项数据。
1 | 1 int sum = 0; |
这是一个OLAP应用,计算全体小于'4321'的f4字段之和。传统上需要读取每一项数据,取出f4,进行比较,然后求和。但是在上面这段代码中,我们可以直接按列读取两列,大幅减小内存读取的次数。
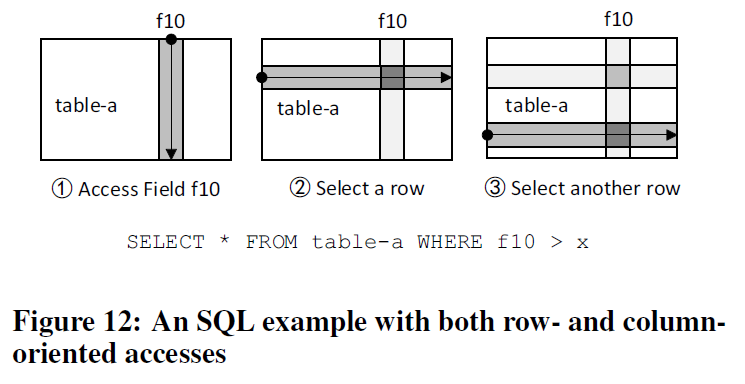
上图中应用是行列混合的。问题与上述OLTP应用类似,但我们也可以利用列读的方式提升效率。这个应用中内存总线上传递的数据均是有用的数据,增加了内存带宽的利用率。
数据布局
我们先前提到,我们有必要在应用层对物理内存上的数据分布进行显式的操控,这里具体来讨论。
数据库通常较大,要存放于内存中,必须进行切割,然后将切割后的块按一定方式放于存储阵列中。切割数据库的技术有很多,例如HDF53,这里不做介绍。这里我们定义,一个块(chunk)是RC-NVM中放置数据的一个矩形单元,可以存于RC-NVM的一个子阵列中。换句话说,当一个表大于RC-NVM的子阵列的大小(此文例子是8MB),或者当一行数据的长度大于子阵列的行长(此文例子是8KB)时,就会被切割。第二种情况甚少在实际情况中出现。
进行切割后,有两个问题需要考虑:块内数据布局与块间数据布局。
块内数据布局
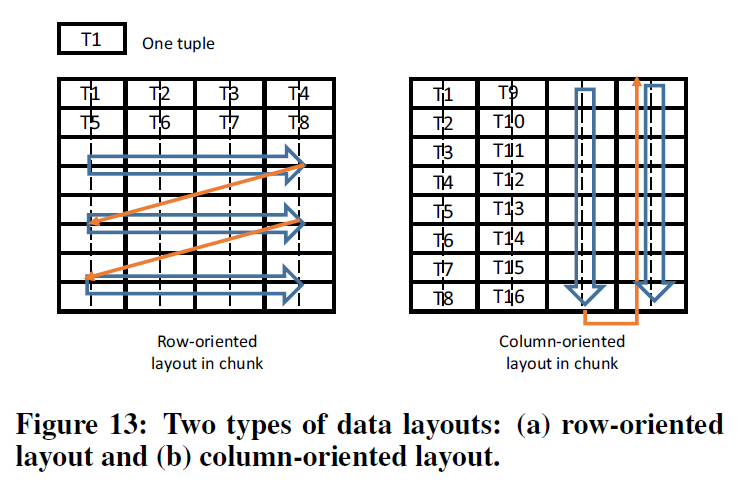
传统上,内存虽然是二维阵列,却实际上是一维的。数据在内存中以左图的方式布局。而对于RC-NVM,有两种布局方式:行向布局与列向布局。
左图行向布局是传统布局方式,各数据项的行内存地址连续排列,与传统IMDB以及内存分配完全兼容,适合按行的读取方式。但是这种布局方式按列读取效率不高。事实上,虽然我们的存储器支持按列读取,但这样的布局下,按列读得的数据不是按顺序排列的(T1之后是T5)。
右图列向布局则更适合列向读取,各项数据按列依次排布于内存中。也即,每一项数据本身虽然是横向放置的,但各项数据却是按列排列的。此时,获取各项数据的同一个字段效率大幅度提升,可以直接应用按列读取的方式。
事实上,OLXP应用应该采用右图的列向布局。因为实际情况中,每项数据长度会远小于RC-NVM的行长,因而每行实际上有较多数据,按列读取数据效率较低,并且,实际情况中连续扫描各项完整数据的需求并不大。
块间数据布局
块间数据布局是个有意思的问题。由于对每个子阵列而言,行列完全对称,因此数据可以旋转后填入子阵列。我们的目标是:使得填入了至少一块数据的子阵列(也即使用的子阵列)数目尽可能少。实际上这是一个经典的问题:可旋转的二维在线装箱问题(two-dimensional online bin packing with rotation)我们可以利用很多已有的工作,例如Fujita的算法4来求解这个问题。
这个问题纯粹是软件级别的,在应用层由数据库内存分配来实现,与硬件无关。
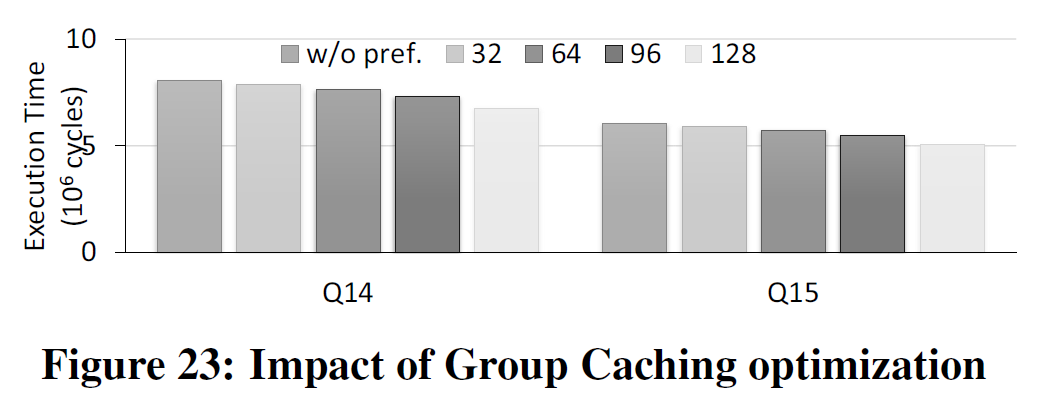
组缓存优化
当数据需要以特定顺序获取时,行向读取效率会降低。先前介绍的都是字段定长(8字节)的情形,但实际情况中字段未必定长,而且也可能超过按列读取的宽度(8字节),这将降低效率。因而我们要在此研究宽字段读取(wide field access)问题。

如图所示,数据中含有Email字段,但其跨了RC-NVM的两列,不可分割。简单回顾一下架构:我们有一个覆盖全列的列缓冲区,但缓存块通常并没有那么大(例如只有64字节,即能存储该列中8行的数据),务必需要注意缓存与内存是分离的,它们在两个不同设备中,不能认为它们自然匹配。
简单地以右侧方式读取(也即两次按列读取)将会使得实际上不可分割的Email字段被分离了。数据以图示的顺序被读取,内存上进行了两次按列读取,但数据被读入的顺序并不正确,当T1至T8的Email被读入时,它们事实上仅获得了一半的数据,对于应用而言,这样的数据是无用的(我们并不能假定这些读过的数据被存下而被后续拼接了,缓存可能会直接将之前的数据丢弃)。列向的读写能够高效遍历整个字段仅当读取顺序不做要求。
正确的方式是以左侧方式读取,但是这需要做四次按列读取,列缓冲区被替换了三次,造成了极大的浪费,列缓冲区被重复地替换了。要正确获得T1的完整Email字段,我们理应在获得前8字节后,立刻获取后8字节。
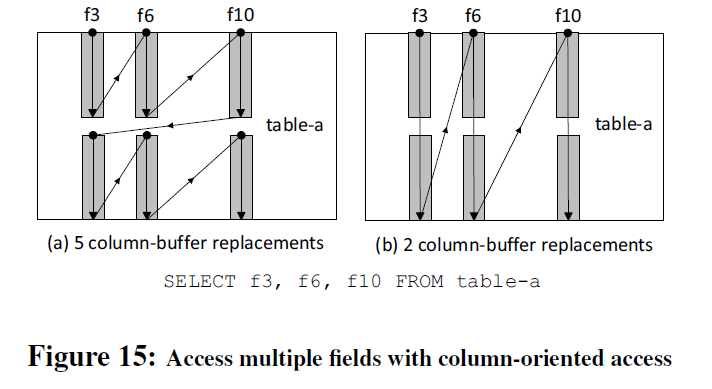
读取多个字段的情形也是类似的。实际上,操作本身对于数据的获取顺序是有要求的。同一项数据的f3、f6、f10字段应该被一起取出。这种Z型的读取极大降低了按列读取的效率。另一方面,我们更不应该在这种情况下转投按行读取。
这也是一种缓存颠簸(cache thrashing)。其实这个问题很容易解决,按照两图中右侧的读法,数据本身都已经被取出了,唯一的问题就在于缓存可能驱逐上一次刚读进来的问题。我们采取一种熟知的技术:缓存固定(cache-pinning)5,具体如下所示:我们按照上述右侧的按列取法,先将T1-T8中所有的前半部分读入缓存,并且固定在缓存中,然后依次如图取完四组数据,数据库从缓存中取走数据,缓存解除对数据的固定,这就是组缓存(group caching)。这个操作是纯粹软件层面的,可以由IMDB发出一条组缓存的指令来完成。
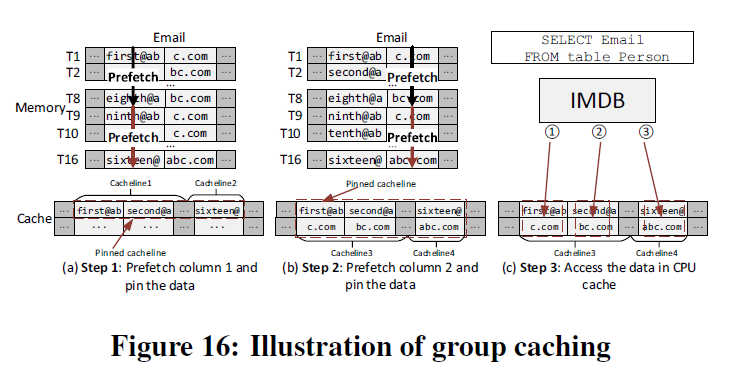
利用组缓存技术,我们在读取一块矩形区域数据时,IMDB本身可以做优化,选择按行或按列读取。组缓存的大小对效率的影响在于:组缓存大时,会使得其它数据更有可能缓存不命中,而组缓存大小也不能超过缓存本身容量;组缓存小时则不一定能够起到效果。
评测
此部分略去。如果未来有时间可能考虑补上这项内容。
仿真配置与测评的代码如上。
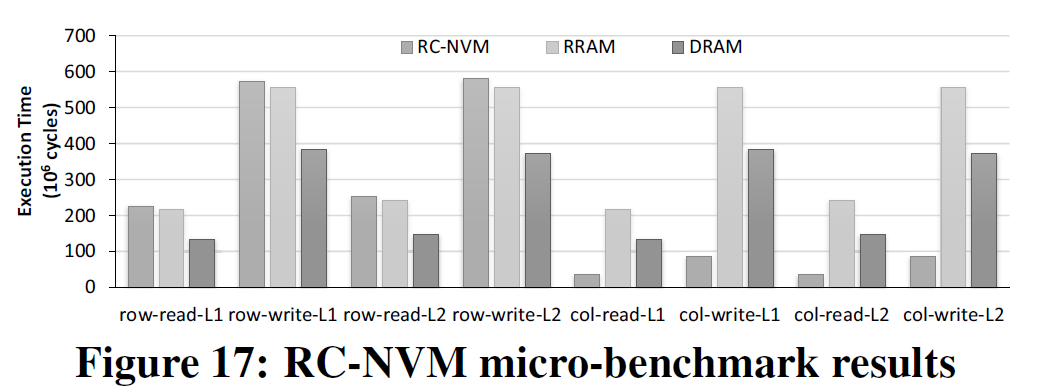
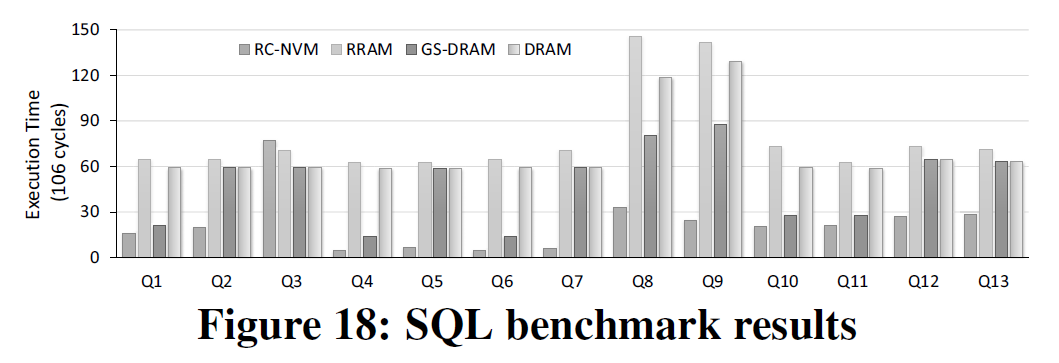
结果如下:
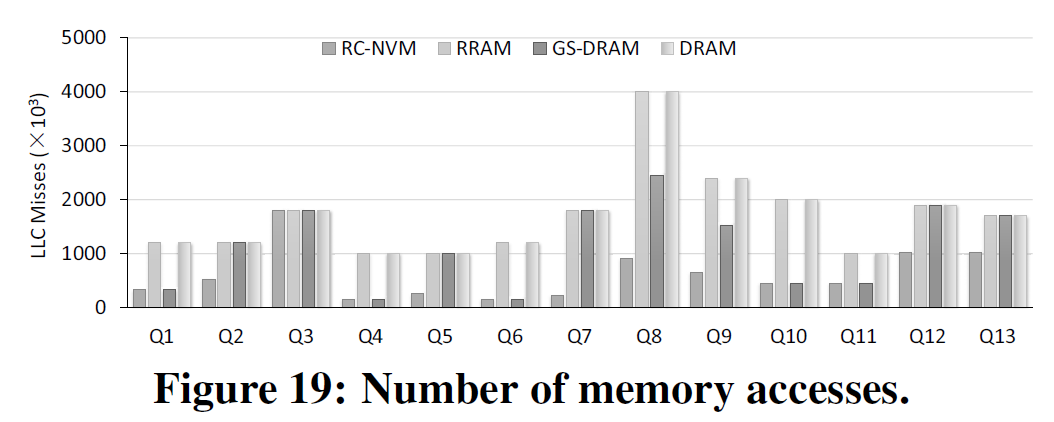
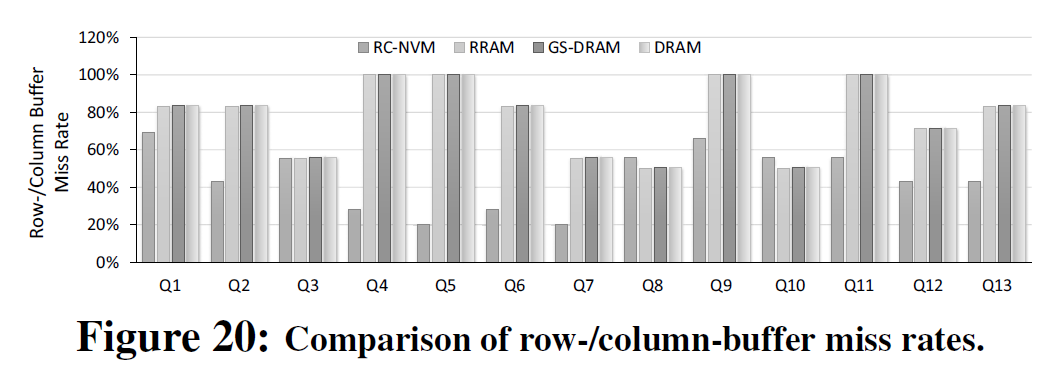
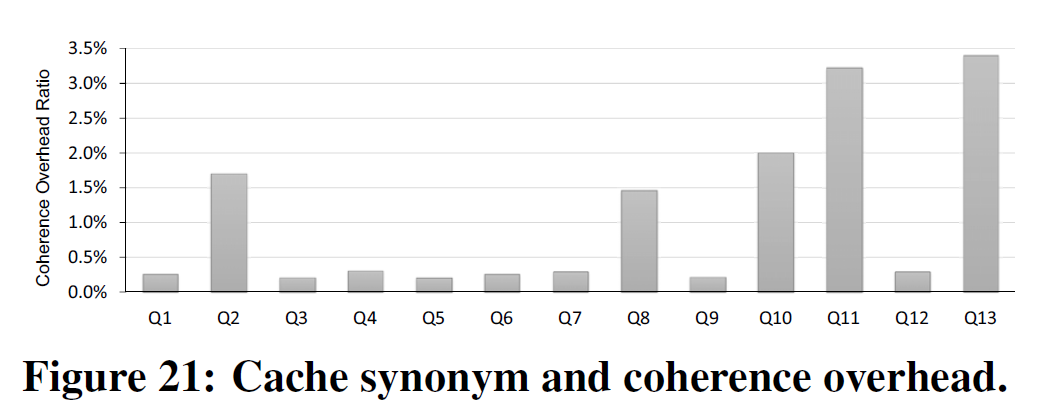
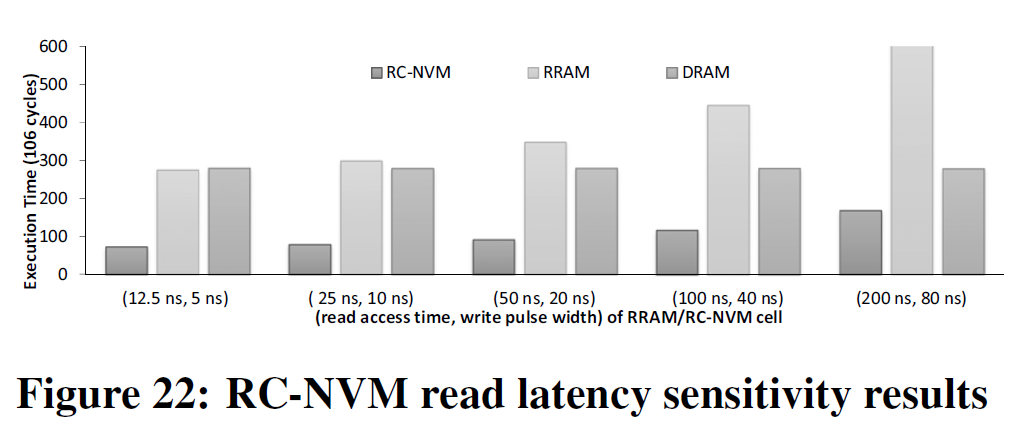
相关工作
具体文献详见原文,此处仅作总结。
内存数据库优化
- 内存相关的处理器流水线停顿分析
- 数据布局优化
- 软件层面的OLXP,如行列混合存储
高性能内存架构
DRAM相关的高性能内存架构也可以移植于RC-NVM上,与此文所述架构结合。
- Redundant Memory Mapping
- SALP
- DRAM与对称式存储的混合架构
- Intel Optane
总结
这是一套完整的从电路到应用层的对称式存储架构设计,在各个层次都有值得学习的地方。总体而言,这样的架构设计充分利用了现有技术,例如与RC-DRAM相比,此架构没有设计新的缓存一致性协议,而是利用了已有的协议。
并且,架构设计中充分的分层是值得学习的。在分层中值得注意的是,一定不能将各个层次混淆,例如:组缓存策略中,缓存的设计与内存本身读写一定要充分区分,不能认为支持了行与列的内存读写,相应的缓存就必然能够按列拼接数据;数据布局的设计也是类似的。一定要注意,在底层出现了新的设计后,向上的每一层接口都要相应地发生改变,但并不用关心下层的具体细节。
不能仅满足于电路设计,一个支持对称式访问的存储器并不必然地能够提升应用的性能。本文给出一个好的例子,设计了一个完整的系统,此后的工作应该考虑参考之进行完整的系统设计方才是有意义的。
总体而言,本文架构设计的思想均是最自然的思想,未必是最好的办法,但大大简化了设计的难度,具体应用上,我认为还有一定的改进空间。在系统设计上,最重要的就是抓大放小,掌握各项内容开销大小的主次才能设计好的系统。
参考文献
Wang, Peng, et al. "RC-NVM: Enabling symmetric row and column memory accesses for in-memory databases." 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2018.↩
Chen, Yen-Hao, and Yi-Yu Liu. "Dual-addressing memory architecture for two-dimensional memory access patterns." Proceedings of the Conference on Design, Automation and Test in Europe. EDA Consortium, 2013.↩
Folk, Mike, et al. "An overview of the HDF5 technology suite and its applications." Proceedings of the EDBT/ICDT 2011 Workshop on Array Databases. ACM, 2011.↩
Fujita, Satoshi, and Takeshi Hada. "Two-dimensional on-line bin packing problem with rotatable items." Theoretical Computer Science 289.2 (2002): 939-952.↩
Zyulkyarov, Ferad, et al. "Method for pinning data in large cache in multi-level memory system." U.S. Patent No. 9,645,942. 9 May 2017.↩