RC-NVM是指Row-Column Non-Volatile Memory,是一种新型的对称式非易失存储器架构。本文是HPCA 2018 RC-NVM: Enabling symmetric row and column memory accesses for in-memory databases1一文的学习总结与分析。
背景介绍
对于关系数据库应用,传统硬盘存储只将小部分数据缓存于内存中,具有高I/O延时,而随着DRAM价格降低、容量提升,IMDB(in-memory database,内存数据库)成为可能。
关系数据库以二维表格存储数据。数据库应用的工作量主要分为两种:OLTP(on-line transactional processing,联机事务处理)与OLAP(on-line analytical processing,联机分析处理)。其中OLTP主要是对数行的读写过程,并且对延时性能要求较高,主要见于交易处理系统。OLAP主要是大量连续跨行、涉及数列的数据处理,例如求列上数据之和,主要见于数据仓库。
同时使用这两种处理方式时,内存中就需要同时常驻存储至少两份数据拷贝,同时二者之间的数据同步也导致分析数据与实时数据之间转换的低响应。OLXP技术混合二者,将数据存于同一个数据库中,但这一技术也使得内存读写的效率降低。这其中的主要原因在于:OLTP主要涉及按行读写数据,而OLAP主要涉及按列读写数据。传统内存只有一个维度,提供从零开始的内存地址,只能以一个方向读写数据,并且传统上数据也按行存于内存中,对于OLTP方式更为友好。此时OLAP访问就会出现跨行的访问(strided memory access),这样的访问使得DRAM的行缓冲区与缓存利用率极低。如果对OLAP进行优化,数据按列存储,OLTP就会出现同样的问题。
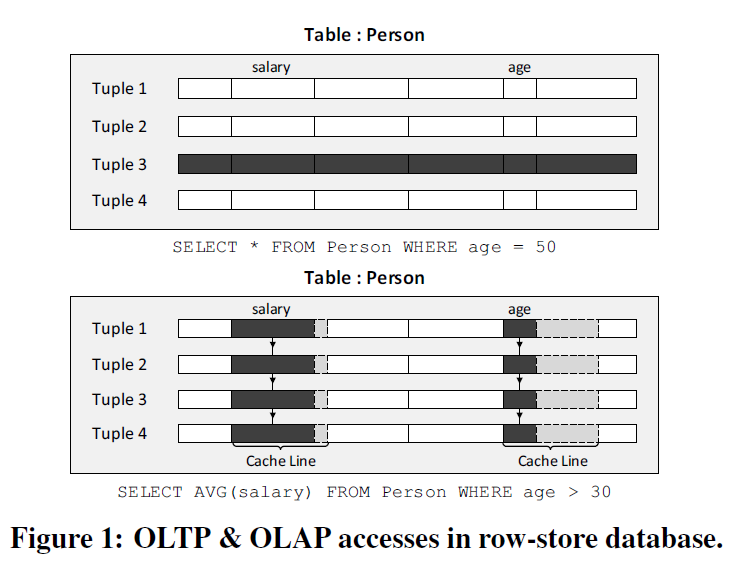
上图为按行存储的数据库的具体形式,其中上半部分展现了一种OLTP操作,下半部分展现了一种OLAP操作,注意到OLAP操作中缓存的利用率较低。
要解决这一问题,同时支持按行读取与按列读取的内存架构是必要的。现有的技术主要有:GS-DRAM、transposable SRAM、RC-DRAM。
GS-DRAM
Gather-Scatter DRAM2是一种十分有趣的内存架构,以后有机会可以再单独写一篇文章介绍。
参考资料可参见https://users.ece.cmu.edu/~omutlu/pub/GSDRAM-gather-scatter-dram_vivek-micro15-talk.pptx
这是在对传统DRAM做极少的改动下,将所读的行中可能需要的列(字段)中数据放于缓存中:
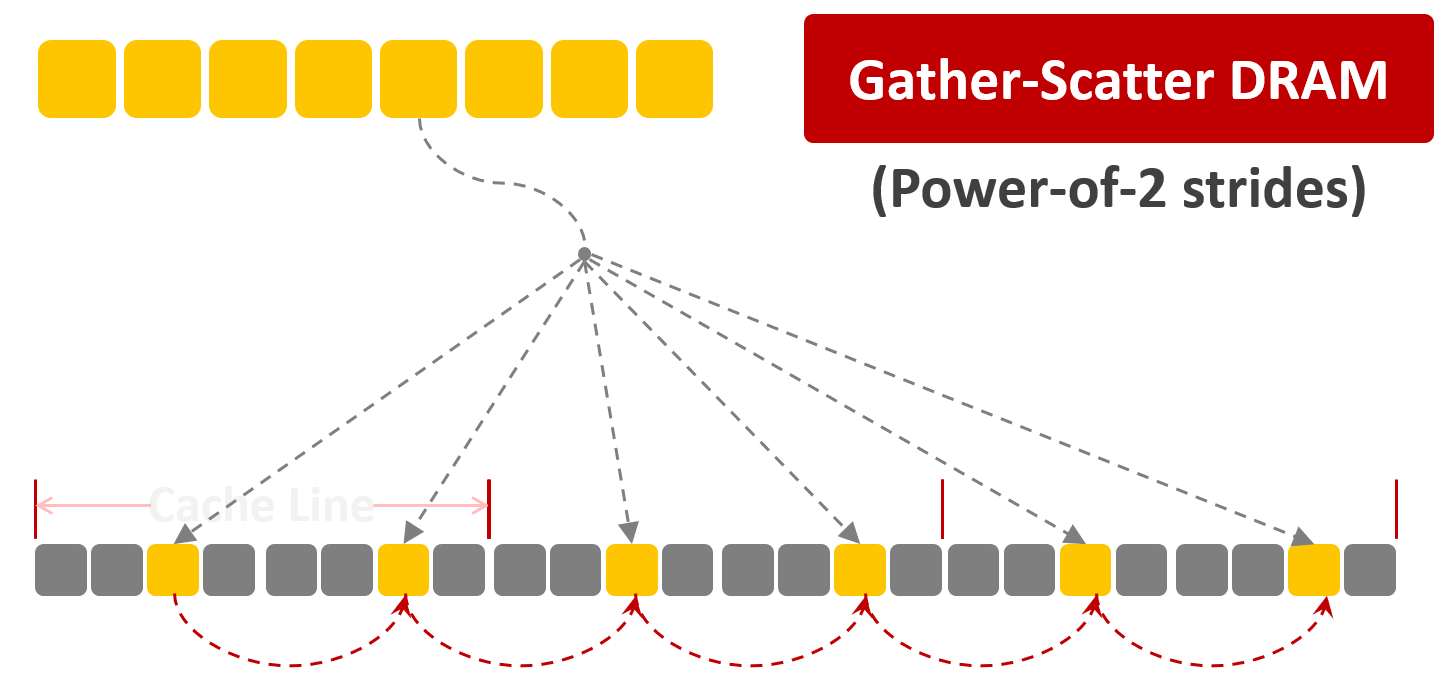
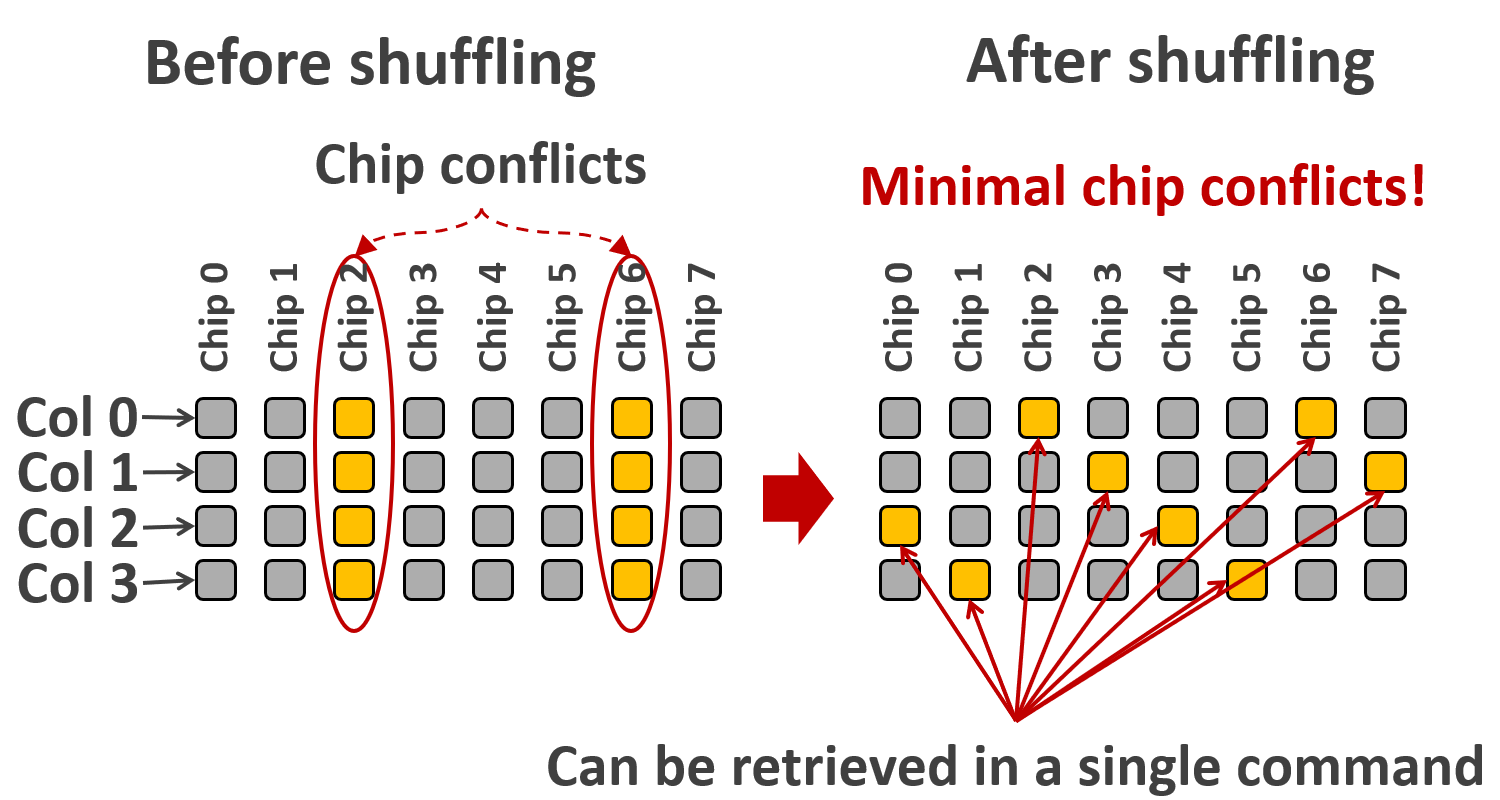
如上所示,缓存中存储的并非是按行读取的数据,而是跨行的字段,这样的架构可以做到行、列都具有较高的效率。具体而言,通过以下两个技术,可以使得每行的数据中对应的同一列(字段)地址错开,这样可以存于缓存中的不同位置,并可以反向推断内存地址(缓存中地址大致等同于内存地址的最末若干位,这种描述不精确,但足以描述这种方法的思想)。
- Column-ID-based data shuffling (shuffle data of each cache line differently)
- Pattern ID – In-DRAM address translation (locally compute the column address at each chip)
然而这个技术有一些明显缺陷:
- 只能利用已经存储于行缓冲区中的数据放入缓存
- 不够灵活,只适用于特定形式,例如跨2的幂的读取
- 当行的大小增大时,效率减低,因为能同时利用的行数减少
- 数据库有多个表时,由于模式增多,复杂度提高
RC-DRAM
RC-DRAM也称为双向可寻址DRAM。这也是一个很重要的内存架构,先前也学习了这个架构,以后如果有时间也需要总结。
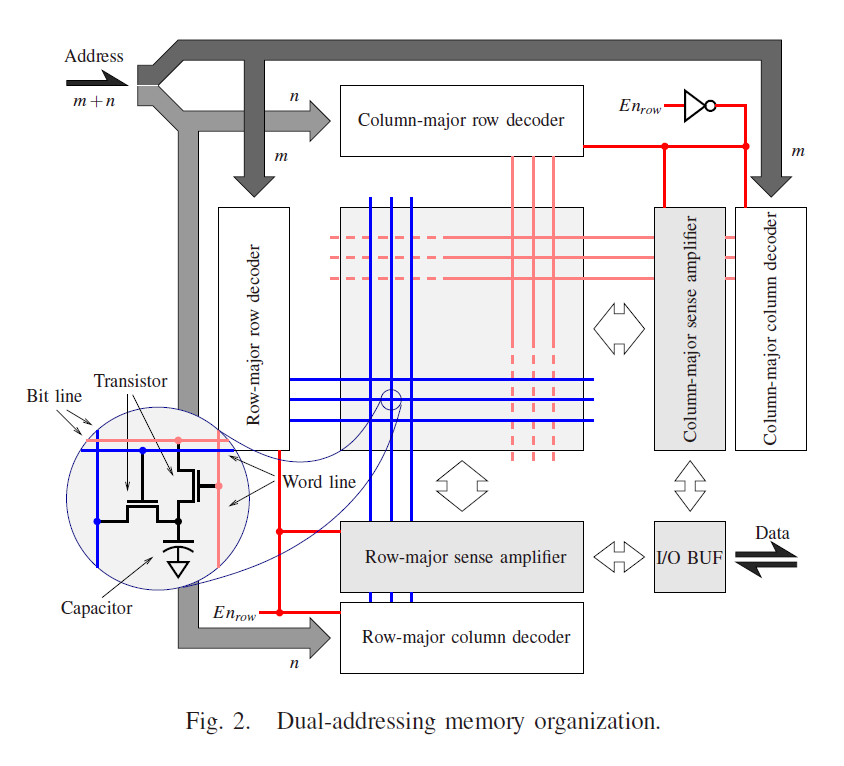
RC-DRAM3是针对现有的DRAM单元进行的直接改进,每个单元含二晶体管、一电容,是完全对称的结构,在阵列级别上能够同时支持按行、按列的读取(并且完全对称)。
这使得按列的读取与按行的读取完全对称,解决了上述的问题。
这种方式需要解决的问题在于,缓存一致性协议需要修正,主要因为此处有两个方向的缓存,保持其同步需要额外的协议。
这种技术的主要问题在于:其各个单元面积的开销过大,甚至超过了直接复制两遍数据(一遍以行、一遍以列)方式的开销(面积开销超过两倍,同等面积容量不足一半)。
Crossbar架构
基于Crossbar架构的非易失存储是一种主流技术,并且十分适于对称式存储器设计。
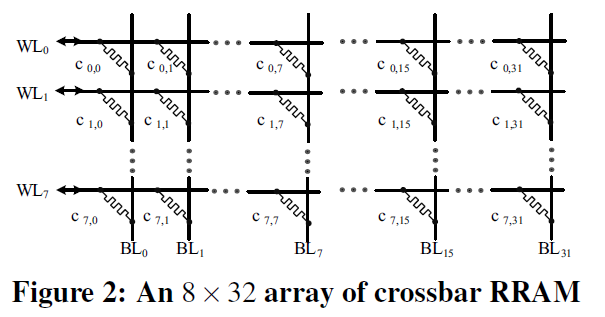
图示为一8*32RRAM构成的Crossbar阵列。RRAM也可以用其它有非易失特性的器件(如PCM)替代。其中每个RRAM单元跨接在字线与位线的交点上,通过行线和列线上施加不同电平可以按行或按列进行读写,具体读写方式不在此赘述。
Crossbar架构的优势在于,每个非易失存储单元本身即完全对称,在架构中按行与按列的读写完全对称。与RC-DRAM相比,其不需要额外的晶体管用于行列读写的控制,因而它的额外面积开销显著更小。
RC-NVM就是采用Crossbar架构进行的设计。
RC-NVM电路设计
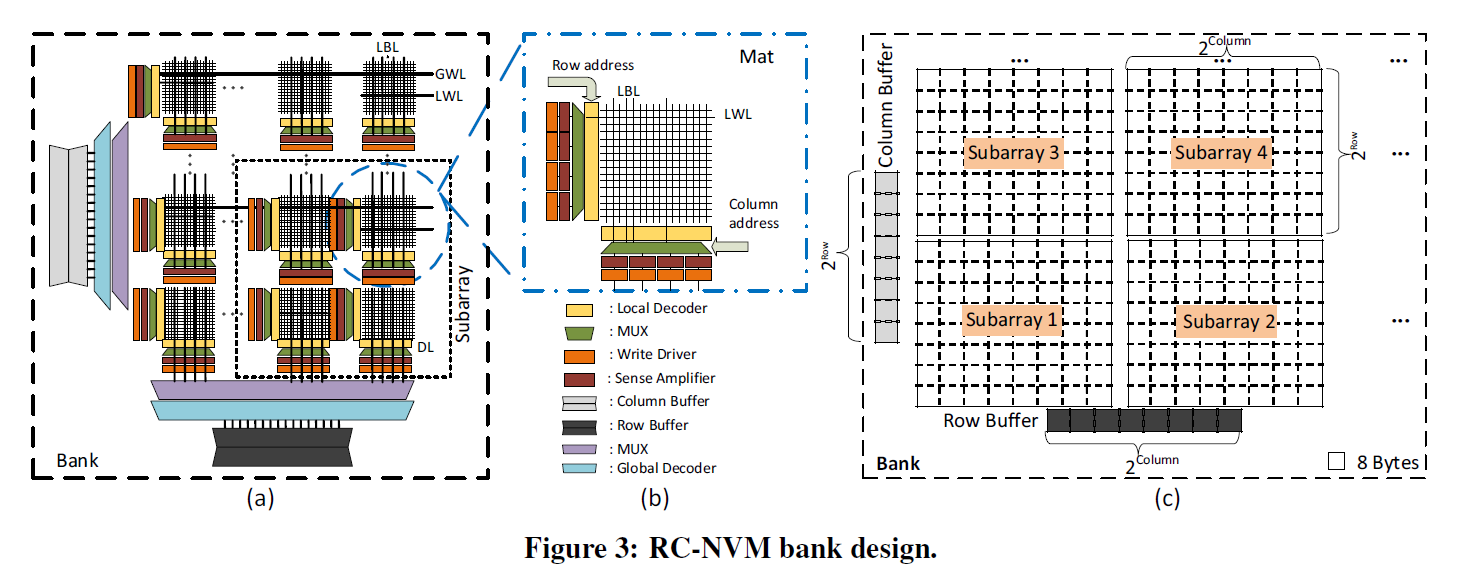
上图为RC-NVM的具体logic bank设计。除去基本的Crossbar阵列外,有一些外围电路。
字线与位线均连接到专用的解码器(decoder),感测放大器(sense amplifier, SA),写驱动器(write driver, WD)之上。这些连接均用多路复用器(multiplexer, MUX)控制,控制信号由内存控制器发出。除去已有的行缓冲区外,还要增加一个列缓冲区。
bank中划分为子阵列(subarray),这是用以按行、按列对称读写的基本读写单元。以行读为例,给定一个访问地址,全局的行解码器作部分解码,激活一个全局字线(global word line, GWL)和一个全局块线(global block line, GBL),然后局部行解码器最终发出一个one-hot信号(一位有效编码,指仅一位为1,其余位均0),激活一个局部字线(local word line, LWL),此后列解码器激活局部位线(local bit line, LBL),最终读出所要读的单元内的数据。随后感测放大器通过数据线(data line, DL)将数据送到行缓冲区。
这是一个经典的层级结构,能在规模增大时有效缓解延时和功耗。
这里会产生一个冲突:当同一个bank中的行与列缓冲区都存有数据中,该行与列交点处的数据被同时存于两个缓冲区中。这产生了经典的一致性问题,当一个缓冲区中该数据修改时,无法保证另一个缓冲区中同一数据被同步修改。这里,增加一个限制:行缓冲区与列缓冲区不能同时使用。当行或列缓冲区要使用时,我们关闭另一个正在使用的缓冲区,将数据写回。这避免了数据的一致性问题,代价是下一次被关闭的这一方向下一次读写时需要再从内存进行读写。然而实验结果表明,这样的代价影响不大。
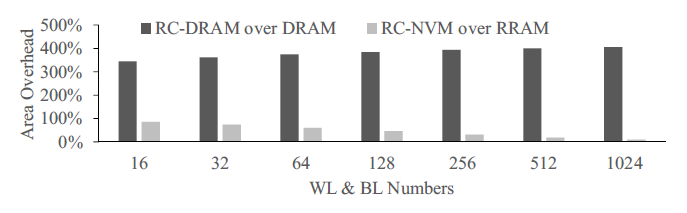
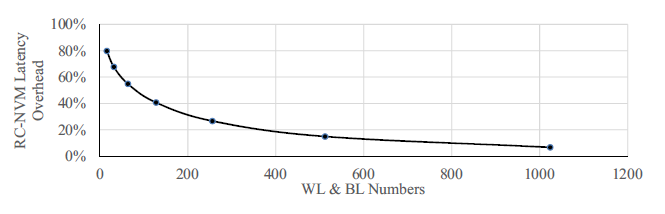
此两图显示了该电路设计的面积与延时特性。
上图是面积特性,横轴表示字线与位线的数目(方阵),纵轴为RC-DRAM与RC-NVM相比传统DRAM或NVM的面积多余开销,这里DRAM与RRAM被设定在同一工艺节点上,容量为4GB,具体评测方法参见文献。可见的是,RC-DRAM具有极大的额外开销(大于两倍),且在电路规模增大时,额外开销更大;但RC-NVM额外开销较小,主要来源于外围电路,因而随着规模扩大,额外开销的的比例在缩小。当字线与位线数为512时,额外面积开销小于20%。
下图为延时特性,延时的额外消耗主要来源于布线上的延迟,主要来自通过更多多路复用的晶体管。但是由于延时主要来自于单元的读写与走线的延时,经过仿真,延时开销在字线与列线为512的规模上增加仅约15%。
下一篇中将介绍RC-NVM上层系统中的架构设计,主要涉及指令集、缓存协议的设计等。
参考文献
Wang, Peng, et al. "RC-NVM: Enabling symmetric row and column memory accesses for in-memory databases." 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2018.↩
Seshadri, Vivek, et al. "Gather-scatter DRAM: in-DRAM address translation to improve the spatial locality of non-unit strided accesses." Proceedings of the 48th International Symposium on Microarchitecture. ACM, 2015.↩
Chen, Yen-Hao, and Yi-Yu Liu. "Dual-addressing memory architecture for two-dimensional memory access patterns." Proceedings of the Conference on Design, Automation and Test in Europe. EDA Consortium, 2013.↩